カプラン=マイヤー推定量(カプラン マイヤー すいていりょう、英: Kaplan-Meier estimator)は、積極限推定量(せききょくげんすいていりょう、英: product limit estimator)とも呼ばれ、生存データから生存関数を推定するために用いられるノンパラメトリック統計量である。医学研究では、治療後に一定期間生存している患者の割合を測定するためによく使われる。他の分野では、カプラン=マイヤー推定量を用いて、失業後に人々が失業している期間の長さや、機械部品の故障までの時間や、果実食動物に食べられてしまうまでの肉果の残存期間を測定することができる。この推定量は、Edward L. KaplanとPaul Meierが米国統計学会誌(Journal of the American Statistical Association)に別々に原稿を提出したことにちなんで命名された。ジャーナル編集者のジョン・テューキーは、彼らの研究を1つの論文にまとめるよう説得した。この論文は1958年に発表されて以来、約61,000回も引用されている。
その生存関数 (寿命が より長くなる確率)の推定量は次の式で与えられる。
ここに、 は少なくとも1つのイベントが発生した時刻、 は時刻 で発生したイベントの数(たとえば、死亡)、そして は時刻 まで生存していることが分かっている(まだイベントが発生していないか、打ち切られていない)個体の数である。
基本的な考え方
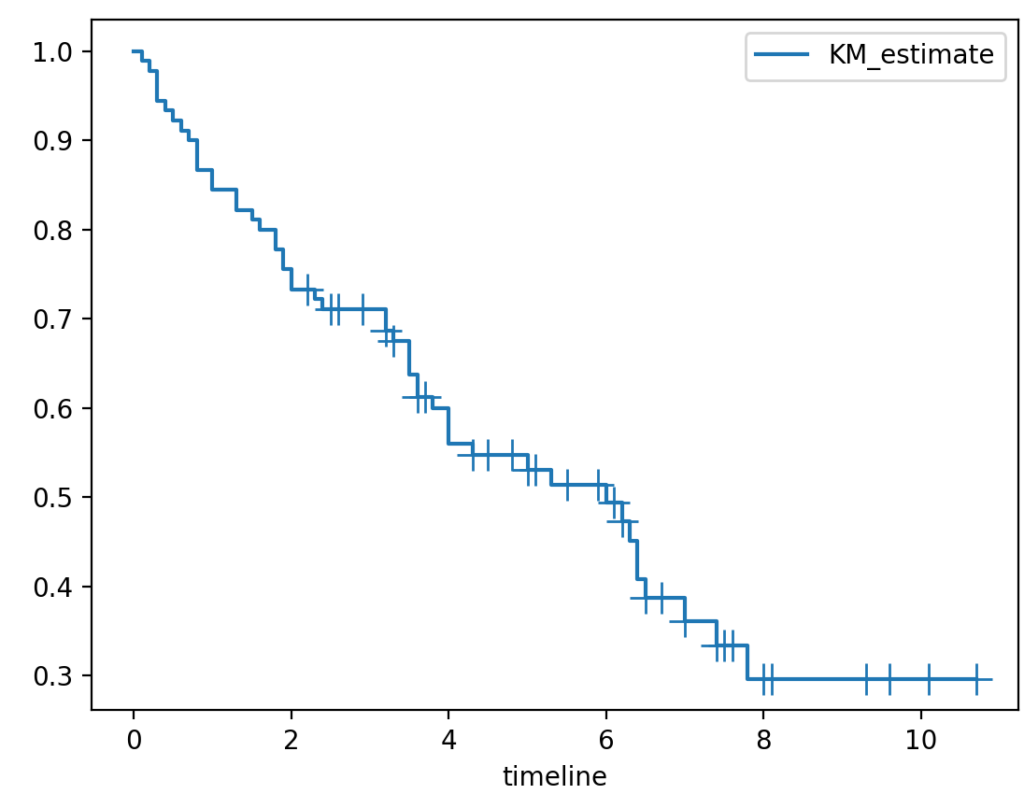
カプラン=マイヤー推定量のプロットは、一連の減少する水平ステップの系列であり、十分に大きな標本サイズの時に、その母集団の真の生存関数に近づく。連続する別個のサンプリングされた観測値(カチッと音がする)間の生存関数の値は一定であると仮定される。
カプラン=マイヤー曲線の重要な利点は、この手法がいくつかのタイプの打ち切りデータ、特に患者が研究から離脱した場合、またはフォローアップに失敗した場合、またはイベントなしで生存している場合に発生する「右側打ち切り」(right-censoring)を考慮に入れることができることである。プロット上では、小さな縦の目盛りが、生存時間が右側打ち切りされた個々の患者を示している。切り捨てや打ち切りが行われない場合、カプラン=マイヤー曲線は、経験分布関数の補集合である。
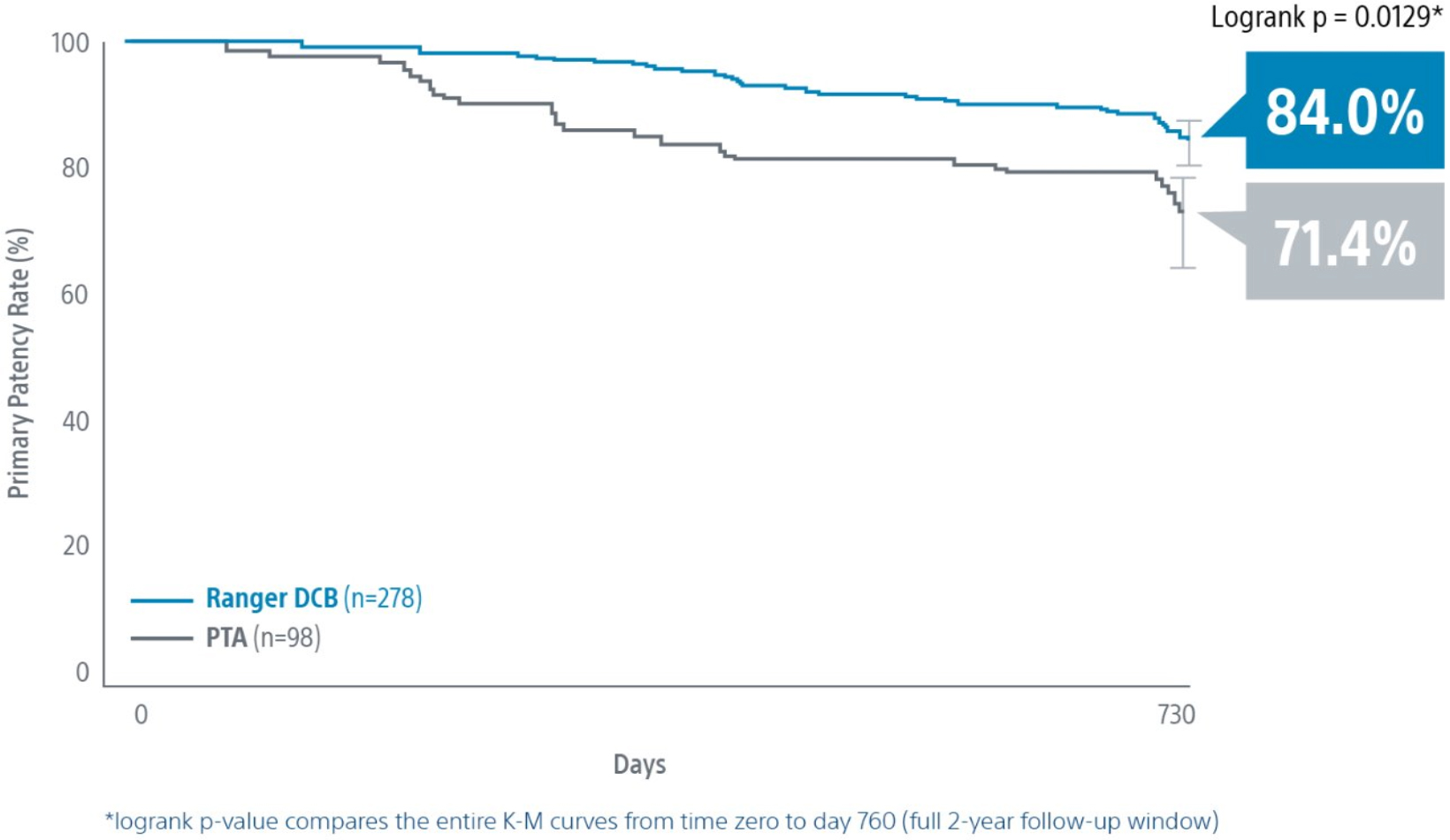
医学統計学では、一般的な応用例として、たとえば遺伝子Aプロファイルを持つ患者と遺伝子Bプロファイルを持つ患者のように、患者をカテゴリーに分類することがある。このグラフでは、遺伝子Bを持つ患者は、遺伝子Aを持つ患者よりも早く死亡する。2年後の生存率は、遺伝子Aの患者では約80%だが、遺伝子Bの患者では半分未満である。
カプラン=マイヤー推定量を作成するには、各患者(または各被験者)について、少なくとも2個のデータが必要である。それらは、最後の観察時の状態(イベント発生または右側打ち切り)と、イベント発生までの時間(または打ち切りまでの時間)の対からなる。2つ以上のグループ間の生存関数を比較する場合、3番目のデータが必要で、それは各被験者のグループ割り当てである。
問題の定義
確率変数 (タウ)を、関心のあるイベントが起こるまでの時間と考えよう(ただし、 である)。上に示したように、目的は、 の潜在的な生存関数 を推定することである。この関数は、
として定義され、 は時間であることを思い出そう。
を独立した同一分布の確率変数とし、その一般分布は で、 は、あるイベント が発生した確率的な時間としよう。 を推定するために利用できるデータは、 ではなく、ペアのリスト である。ここで、 について、 は固定の決定論的整数で、イベント の打ち切り時間(censoring time)であり、 である。特に、イベント のタイミングについて利用可能な情報は、イベントが固定時間 の前に起こったかどうかであり、もし起こった場合は、イベントの実際の時間も利用可能となる。課題は、このデータをもとに を推定することである。
カプラン=マイヤー推定量の導出
ここでは、カプラン=マイヤー推定量の2つの導出方法を示す。どちらも生存関数を、ハザード(hazard)または死亡率(mortality rates)と呼ばれる観点で書き換えることに基づいている。ただし、これを行う前に、ナイーブ推定量を考える価値がある。
ナイーブ推定量
カプラン=マイヤー推定量の能力を理解するために、まず、生存関数のナイーブ推定量(naive estimator)を説明する価値がある。
とし、 とする。基本的な議論により、以下の命題が成立することがわかる。
- 命題1:イベント の打ち切り時間 が () を超える場合、 である場合に限り、 になる。
となるような があるとしよう。上記の命題から、
が成り立つ。
とし、 のものだけ、つまり時刻 以前に結果が打ち切られなかった事象を考えよう。 を の要素の数としよう。なお、集合 は確率的ではないので、 も確率的ではないことに注意を要する。さらに、 は、共通パラメータ を持つ独立同分布のベルヌーイ確率変数の列である。 と仮定すると、
を用いて を推定することになる。ここで、 は を意味するため、2番目の等式が続く。最後の等式は単に表記法の変更である。
この推定量の質は、 の大きさによって決まる。これは、 が小さい場合に問題となる、これは定義上、多くのイベントが打ち切られた場合に起こる。この推定量の特に不快な特性は、おそらくそれが「最良」の推定量ではないことを示唆しており、それは打ち切り時間が より前のすべての観測を無視することである。直感的には、これらの観測はまだ に関する情報を含んでいる。たとえば、 の多くのイベントで、 も成り立つ場合、イベントが早期に起こることが多いと推測できる。これは、 が大きいことを意味し、 を介して、 は小さくなければならないことを意味する。ただし、このナイーブ推定法では、この情報は無視される。そこで問題となるのは、すべてのデータをより有効に利用できる推定量が存在するかどうかである。これを実現したのが、カプラン=マイヤー推定量である。なお、打ち切りが行われていない場合には、ナイーブ推定量を改善することはできないので注意を要する。したがって、改善できるかどうかは打ち切りが行われているかどうかに決定的に依存する。
プラグインアプローチ
基本的な計算によって、
となり、ここで最後の等式は が整数値であることを利用し、最終行で
を導いた。
等式 を再帰的に展開すると、
となる。
ここで、 となることに注意すること。
カプラン=マイヤー推定量は、各 がデータに基づいて推定され、 の推定量はこれらの推定量の積として得られる「プラグイン推定量」(plug-in estimator)と見なすことができる。
あとは、 をどのように推定するかを指定するだけである。命題1により、 となるような任意の に対して、 と がともに成立する。したがって、 となるような任意の に対して、
となる。
上記のナイーブ推定量の構築と同様の推論により、
という推定量が得られる(「ハザード率」 の定義において、分子と分母を別々に推定することを考えてみよ)。そして、カプラン=マイヤー推定量は、
で与えられる。
記事の冒頭で述べた推定量の形式は、さらにいくつかの代数を用いて得られる。そのためには、 と記述する。ここで、保険数理の用語を用いて、 は時刻 における既知の死亡者数であり、 は時刻 において生存している人の数とする。
なお、 であれば、 であることに注意を要する。このことは、 を定義する積から、 の項をすべて除外できることを意味する。そして、、、 の時、 を時間 とすると、冒頭に述べたカプラン=マイヤー推定量の形、
になる。
この推定量は、ナイーブ推定量とは対照的に、利用可能な情報をより効果的に利用していることがわかる。前述の特殊なケースでは、多くの初期イベントが記録されている場合、推定量は1未満の値を持つ多くの項を乗算するため、その結果、生存確率が大きくならないことを考慮に入れよ。
最尤推定量としての導出
カプラン=マイヤー推定量は、ハザード関数の最尤推定から導出できる。より具体的には、イベントの数を 、時刻 でのリスクのある個人の総数を とすると、離散ハザード率 は、時刻 でイベントが発生した個人の確率として定義できる。この場合、生存率は次のように定義でき、
時刻 までのハザード関数に対する尤度関数は、
となり、したがって対数尤度は次のようになる。
に対する対数尤度の最大値は、
と求められる。ここでハット記号()は最尤推定を表すのに用いられている。この結果から、次のように書くことができる。
利点と限界
カプラン=マイヤー推定量は、生存分析で最も頻繁に使用される手法の1つである。この推定量は、回復率、死亡の確率、および治療の有効性を検討するのに有用である。その共変量で調整された生存率を推定する能力には限界がある。共変量で調整された生存率を推定するには、パラメトリック生存モデルおよびCox比例ハザード検定が有用であろう。
統計学的考察
カプラン=マイヤー推定量は統計量であり、その分散を近似するためにいくつかの推定量が使用される。最も一般的な推定量の1つはGreenwoodの式である。
ここで、 は症例数、 は観測の総数で、 である。
場合によっては、異なるカプラン=マイヤー曲線を比較したいことがある。これは、ログランク検定、およびCox比例ハザード検定によって行うことができる。
この推定量で使用できる他の統計量は、Hall-Wellnerバンド(Hall-Wellner band)および等精度バンド(equal-precision band)である。
ソフトウェア
- Mathematica: 組み込み関数
SurvivalModelFit で生存モデルを作成。
- SAS - カプラン=マイヤー推定量は
proc lifetest プロシージャで実装されている。
- R - カプラン=マイヤー推定量は、
survival パッケージの一部として利用可能である。
- Stata - コマンド
sts は、カプラン=マイヤー推定量を返す。
- Python -
lifelines パッケージにはカプラン=マイヤー推定量が含まれている。
- MATLAB -
ecdf 関数に 'function','survivor' 引数を指定すると、カプラン=マイヤー推定量を計算したり、プロットしたりすることができる。
- StatsDirect - カプラン=マイヤー推定量は
Survival Analysis メニューに実装されている。
- SPSS - カプラン=マイヤー推定量は、
Analyze > Survival > Kaplan-Meier... メニューに実装されている。
- Julia -
Survival.jl パッケージには、カプラン=マイヤー推定量が含まれている。
参照項目
- 生存分析
- 超過頻度
- 半数致死量
- ネルソン=アーラン推定量
脚注
推薦文献
- Aalen, Odd; Borgan, Ornulf; Gjessing, Hakon (2008). Survival and Event History Analysis: A Process Point of View. Springer. pp. 90–104. ISBN 978-0-387-68560-1
- Greene, William H. (2012). “Nonparametric and Semiparametric Approaches”. Econometric Analysis (Seventh ed.). Prentice-Hall. pp. 909–912. ISBN 978-0-273-75356-8. https://books.google.com/books?id=-WFPYgEACAAJ&pg=PA909
- Jones, Andrew M.; Rice, Nigel; D'Uva, Teresa Bago; Balia, Silvia (2013). “Duration Data”. Applied Health Economics. London: Routledge. pp. 139–181. ISBN 978-0-415-67682-3. https://books.google.com/books?id=7tdcCol9mNEC&pg=PA141
- Singer, Judith B.; Willett, John B. (2003). Applied Longitudinal Data Analysis: Modeling Change and Event Occurrence. New York: Oxford University Press. pp. 483–487. ISBN 0-19-515296-4. https://books.google.com/books?id=PpnA1M8VwR8C&pg=PA483
外部リンク
- Dunn, Steve (2002年). “Survival Curves: Accrual and The Kaplan–Meier Estimate”. Cancer Guide. 2002年6月14日時点のオリジナルよりアーカイブ。2021年10月10日閲覧。
- Staub, Linda; Gekenidis, Alexandros (Mar 7, 2011). “Kaplan–Meier Survival Curves and the Log-Rank Test”. Survival Analysis. Seminar for Statistics (SfS). Eidgenössische Technische Hochschule Zürich (ETH) [Swiss Federal Institute of Technology Zurich]. http://stat.ethz.ch/education/semesters/ss2011/seminar/contents/handout_2.pdf
- Three evolving Kaplan–Meier curves - YouTube